Java fuzzing with JQF + afl
Mon, Aug 19, 2019 ❝Performing fuzzing in Java using afl and JQF.❞Contents
Many applications require user input or otherwise untrusted input, in order to do their work. One typically cannot assume that this input is always exactly according to the prescribed format and does not contain any invalid or illegal content. However, testing for every possible violation of the prescribed format is often not feasible.
Fuzzing helps with this by automatically generating variations in input and offering it to process by the application. Anything that crashes the application is then stored such that developers can later look at these cases and modify the code accordingly, typically to make the application more robust. Inputs are varied by using a range of mutation techniques, such as splicing and bitflipping. To gain more insight into the performance and quality of generated input, instrumentation is used as a way to discover if new paths have been taken. Instrumentation allows the fuzzer to discover if input was of particular interest.
In case of Java, we can assume that the traditional application crash cannot occur because the Java run-time is sufficiently robust. However, the Java application itself may still fail. JQF offers a framework to put in between Java and afl (the fuzzer) in order to interpret Java’s failure characteristics, such as uncaught exceptions, and trigger appropriate responses, such as registering the used input as a “crasher”.
Exactly because fuzzing uncovers the hidden issues that cripple an application’s stability, robustness and quality, it becomes possible to take the next step in improving these properties of the application. In addition, it may help to gain insight into the application and you may conclude that some of the uncovered issues need to be fixed outside of this application. Even so, it gives valueable feedback useful for improvement.
For applications written in non-memory-managed languages, fuzzing has the additional benefit of uncovering bad memory management resulting from unanticipated cases. Security researchers may apply fuzzing in order to find such cases as they are often entry-points to vulnerabilities in the application. Memory-managed languages, such as Java, do not have this class of problems.
How does fuzzing work?
A fuzzer reads a set of user-provided inputs (“seeds”). It passes these inputs, one at a time, to the fuzzing driver. The driver calls into the code-to-be-fuzzed with the input provided by the fuzzer and takes the result. If everything goes well, which is necessary for seed inputs, the fuzzer will gain some insight into the application logic and it registers some unique, useful inputs for later use.
Next, once all seeds have been processed, inputs get generated. The fuzzer generates input by mutating existing inputs (initially just the seeds, but may also include inputs discovered by the fuzzer itself) and feeds that to the application. It then checks the kind of results that it receives.
In case of:
- input crashes the application: store the input and results for further investigation. Crashers are considered bad.
- input visits only known paths, delivers result: not really valuable input, pay no further attention to it.
- input visits new paths, delivers results: valuable input, store for later use.
- input causes exception: store the input and results for further investigation.
- input does not produce results for an extended amount of time: input are recorded as “hangs” for further investigation.
As valuable inputs are stored, the number of inputs for use as a basis for mutation increases. This then feeds input more variations of mutation.
Crashers (and hangs) are stored for further investigation. These are the fruits of successful fuzzing. It is very hard to prove that an application that seems to work will continue to work for all possible cases. However, if failures are found - which is what fuzzers exist for - then you have concrete evidence. Investigate the inputs of the crashers and hangs, and use the findings to fix your application.
JQF with afl
afl by itself is capable of fuzzing, but is designed for use with native binaries. In case of the Java run-time, this is a problem: afl cannot detect whether an exception has occurred. JQF is the “proxy” that resolves this issue.
JQF is a fuzz-testing platform that can leverage a number of engines for fuzzing: afl, Zest, PerfFuzz. In this case, we make use of afl.
An instruction on using JQF with afl provides the basic knowledge to get started.
Getting started
- Download and build afl.
- Set environment variable
AFL_DIRto the location of theafl-fuzzbinary. - Download and build jqf.
- Make sure that
jqf-afl-fuzzcan be called, i.e. available on thePATH. (Not needed if directly called. However, it is necessary if called through maven plug-in.) - Start
jqf-afl-fuzzwith appropriate program arguments to start fuzzing.
Now, to actually start fuzzing, we first need to construct a driver that shapes the input into the right structure for consumption by the logic-to-be-fuzzed.
Writing a driver for JQF framework
JQF builds on top of JUnit’s QuickCheck framework. One can use JUnit’s Assert and Assume logic to respectively identify problems, and to accept specific circumstances, e.g. accept certain exceptions.
The fuzzing driver itself does not need to be complicated. Simply acquire the input provided by the fuzzer, shape it into a useful format, then feed it into the logic-to-be-fuzzed.
For more complex data structures, it is worthwhile to look at the combination of JQF + Zest. Zest is able to work with Java classes, meaning that you will not have to shape binary input into a suitable format. This article will not look into Zest, though.
@RunWith(JQF.class)
public class ParserDriver {
@Fuzz
public void fuzzInput(InputStream input) throws IOException {
byte[] data = new byte[4096];
int length = input.read(data);
try {
assertNotNull(parse(new String(data, 0, length, UTF_8)));
} catch (ProtocolException e) {
assumeNoException(e);
}
}
}
Let’s have a look at the specifics of this Driver code from the example:
- Read at most 4096 bytes of input. (May be less. It depends on the input that
aflprovides.) - Convert input to UTF8-encoded string, as this parser expects strings as input.
- We always expect some message in return or an exception. Assert that the result is never null.
ProtocolExceptionis an expected exception for some cases, so do not consider that a crash, but instead consider it a successful run with this exception as the result.Assume.assumeNoExceptionis used to accept the exception as an acceptable outcome, i.e. not a crash.- Any other exception is considered a crash.
@RunWith(JQF.class)annotation to indicate requirement to run using the JQF framework.@Fuzzannotation to indicate a fuzzing driver method. Note that the method signature for JQF + afl is:- No return type.
- Single parameter, having type
InputStream.
InputStreamis the interface that gives access to the data provided by the fuzzer.
Note: you might want to allocate the 4096-byte data variable once in the class instance and reuse it infinitely. However, I am not yet familiar enough with JQF to know whether or not this will cause any data races.
Once the driver is written, we can start the fuzzer: jqf-afl-fuzz -v -c target/my-library-jar-with-dependencies.jar:target/test-classes -i src/test/seeds my.library.ParserDriver fuzzInput
Let’s disect the command:
- classpath-entry
target/my-library-jar-with-dependencies.jaris your library. For convenience, a single-jar assembly will ensure that all necessary dependencies are available on the classpath. - classpath-entry
target/test-classesto access your fuzzing driver class. src/test/seedsas the directory that contains the original input data.my.library.ParserDriverthe reference to your fuzz driver.fuzzInputthe name of the fuzzing method.
Once the fuzzer is running, you will have to wait for your results to flow in. In the best case, no crashers or hangs are found. In other cases, the occasional crash or hang will be discovered and their inputs will be stored separately to allow for easy reproduction.
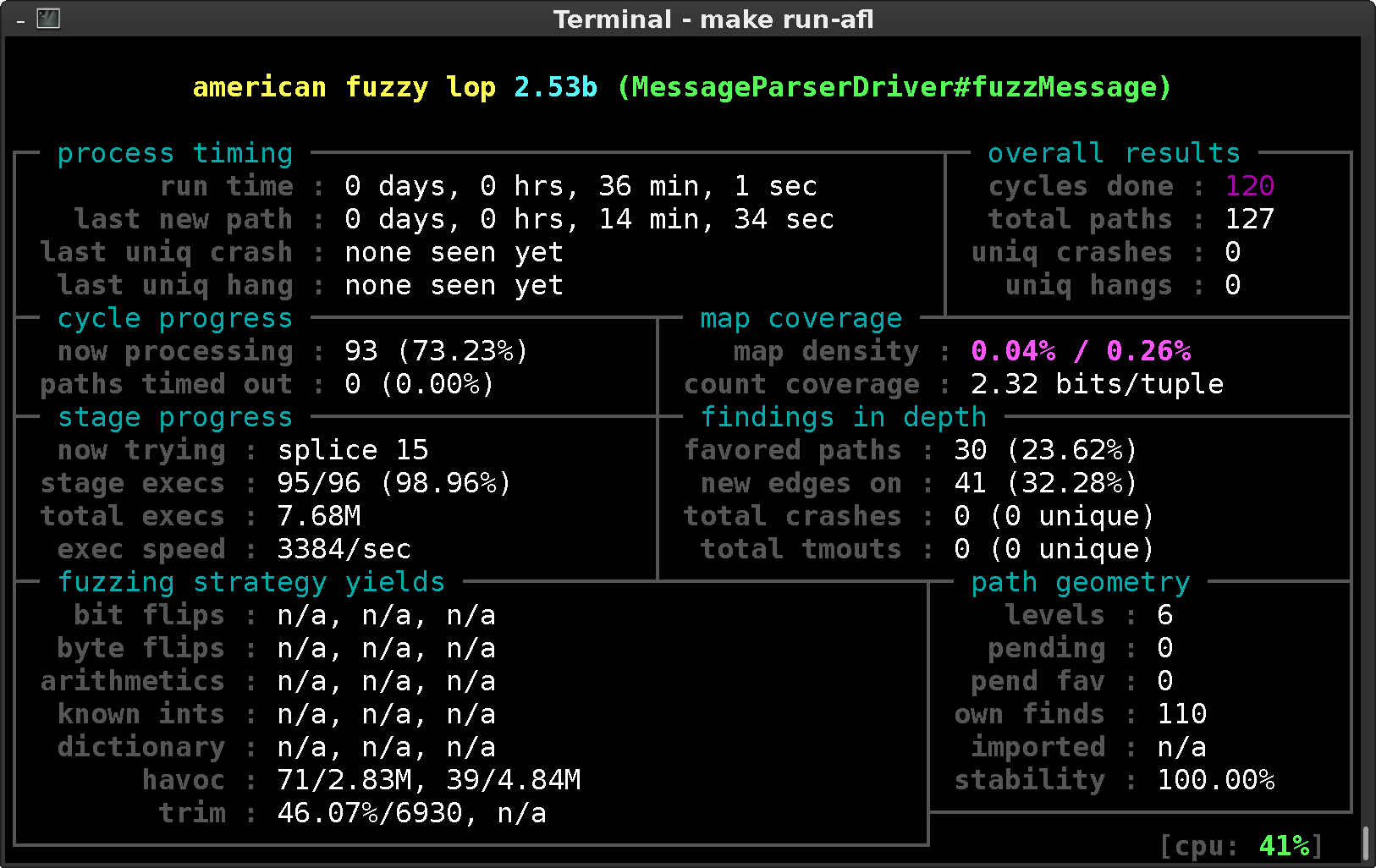
Fuzzing is not an exact science. It is based on smart input mutation, brute force execution and insightful analysis. The right moment to stop, is therefore not exact. One can check the time a crash or hang was last discovered, or when afl last discovered a new logic path. This information can be found in the process timing section. Of course, common sense also helps. If you find a lot of crashers in the first few minutes, it makes sense to fix these first and then restart given a more robust, reliable situation.
Results
After starting the fuzzer and letting it run for a while, there comes a time that we need to evaluate the results.
The JQF log gives an indication on when newly loaded classes are touched (and thus instrumented) for the first time. Or, which classes could not be instrumented. In case such warnings occur in critical code sections, you might need to investigate as afl relies on instrumentation output to discover its input quality.
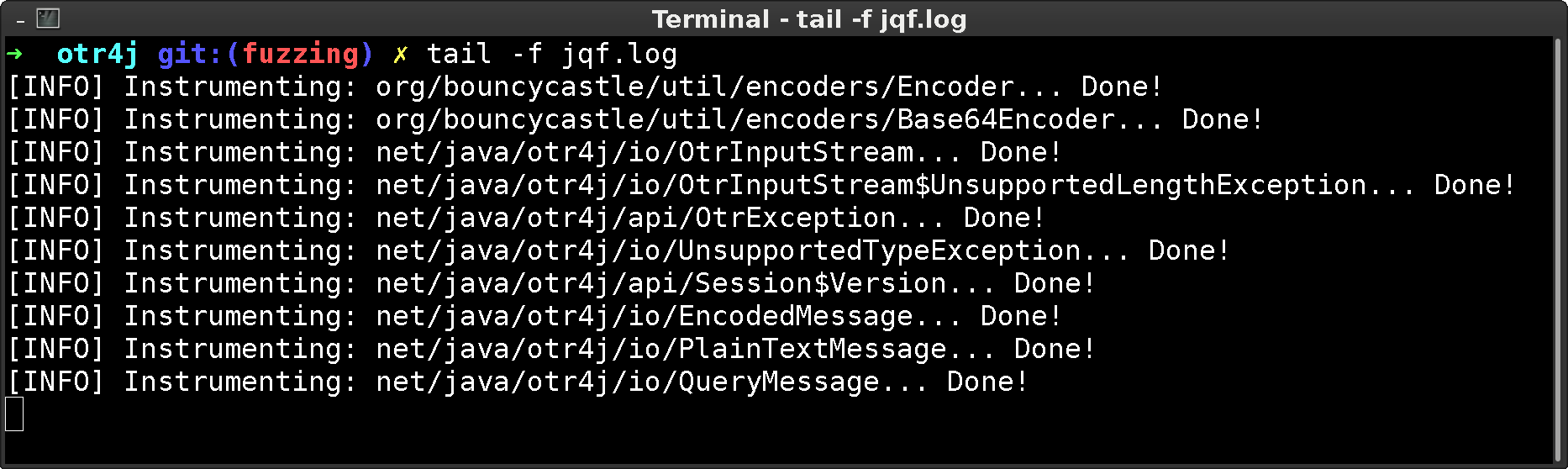
Results are stored as follows:
jqf.log- contains the run-time information during fuzzing and stack trace dumps after executionfuzz-results/:crashes/- any inputs that caused crashes, with additional informationhangs/- any inputs that caused hangs, with additional informationqueue/- all of the known inputs: initial seeds and input-mutations discovered by aflfuzz_bitmapfuzzer_statsplot_data
Findings
Now, once you have done a significant amount of fuzzing, we should have some crashers and hangs to work with.
Typical findings for Java are of the following nature:
- out-of-bounds exceptions, e.g. for arrays, string indexing, list indexing, etc. Given arbitrary mutation, inputs are no longer perfect and minor assumptions are easy to overlook.
- unchecked exception, in case of incomplete or careless user input validation before use. This may be either one of the standard run-time exceptions. Or it may be library-specific and during development we have overlooked the possibility for the exception to occur.
- ill-structured logic, may inadvertently guide you into infinite loops, or down the wrong logical path, and other such issues.
- overflowing of primitives, unexpectedly inputs may inadvertently cause an overflow of primitive types. One may not have taken overflows into account, which - after overflowing - might lead the program into incorrect logic paths or lead to incorrect results.
- off-by-one on semantic boundaries, in case of programming errors, such as mistakes in value comparisons in conditions, that may not have been uncovered by conventional tests.
Given the stack traces dumped in jqf.log and the inputs gathered in the fuzz-results directory, one can then start reproducing these errors and fix them.
Conclusion
Fuzzing will help you to discover more obscure bugs through its input mutation. In particular the fact that the input generated by a fuzzer is less predictable than human-constructed test cases, is beneficial for discovering (unexpected) issues.
For memory-managed languages, it helps to discover implementation issues or semantically incomplete case handling. For non-memory-managed languages, it additionally helps to discover entry-points to potential security vulnerabilities.